Orchestration Wars - Airflow
Published on Dec 2, 2024
Last updated on Apr 5, 2025
22 min read

Prelude
We recently discussed an event-driven design to link different pipelines while decoupling their maintenance. A topic present throughout was orchestration in general. How do we link workflows that could be as small as a bash script to large complex pipelines spanning multiple systems? What is the simplest yet effective way of doing it? Isn’t there a tool that could do this for us?
Well of course there is!
Several actually. There’s airflow… yes, dagster too. Ah didn’t Spotify create luigi? Or they changed at some point? Hmm there are also prefect and mage.ai I recall hearing about.
What about the big platforms? They surely have orchestration built-in!
Oh that’s right! Databricks, AWS Step Functions, Foundry …
Oh god which one to pick?

Well the easy answer is the one most available :)
But what if you can choose? Maybe you are one of the lucky ones with the freedom to do so!
So let’s try to look into that.
Hey, there are already plenty of comparison articles!
True. The point here is not to add yet another ChatGPT-like article to the void. No sales pitch either.
What we want is to cast a wide net over the practical aspects of using such a tool. Is the deployment complex? Does it handle our use cases? Is it flexible enough yet easily maintainable? Will it still be around in the coming years? What do we need to know before migrating to this tool?
You guessed it; this is going to be a series of articles. We will try to answer all of those questions without going too deep, more from the perspective of an engineer using it. The sections should be readable on their own, so feel free to jump ahead; it is a pretty big blogpost.
So how about we begin with OG Airflow?
History Lesson
Airflow started at Airbnb around 2014, directly as open source. It is written in Python and became a top-level project of The Apache Software Foundation in 2019. The project has over 36K stars on Github and shows quite a lot of activity. There is a claim of hundreds of active users.
Why do we care?
Simply to get a better picture of whether the project is maintained and will exist in several years. Based on all the above, looks like a clear yes.
Core Concepts
Airflow is a platform for workflows. A workflow here is conceptually a DAG built out of Tasks which are the units of work. Tasks can be either Operators, such as a Python script or a database operation, or Sensors, which are waiting for external events.
The core components are:
- scheduler to trigger and submit tasks,
- webserver for the UI,
- metadata DB to store state.
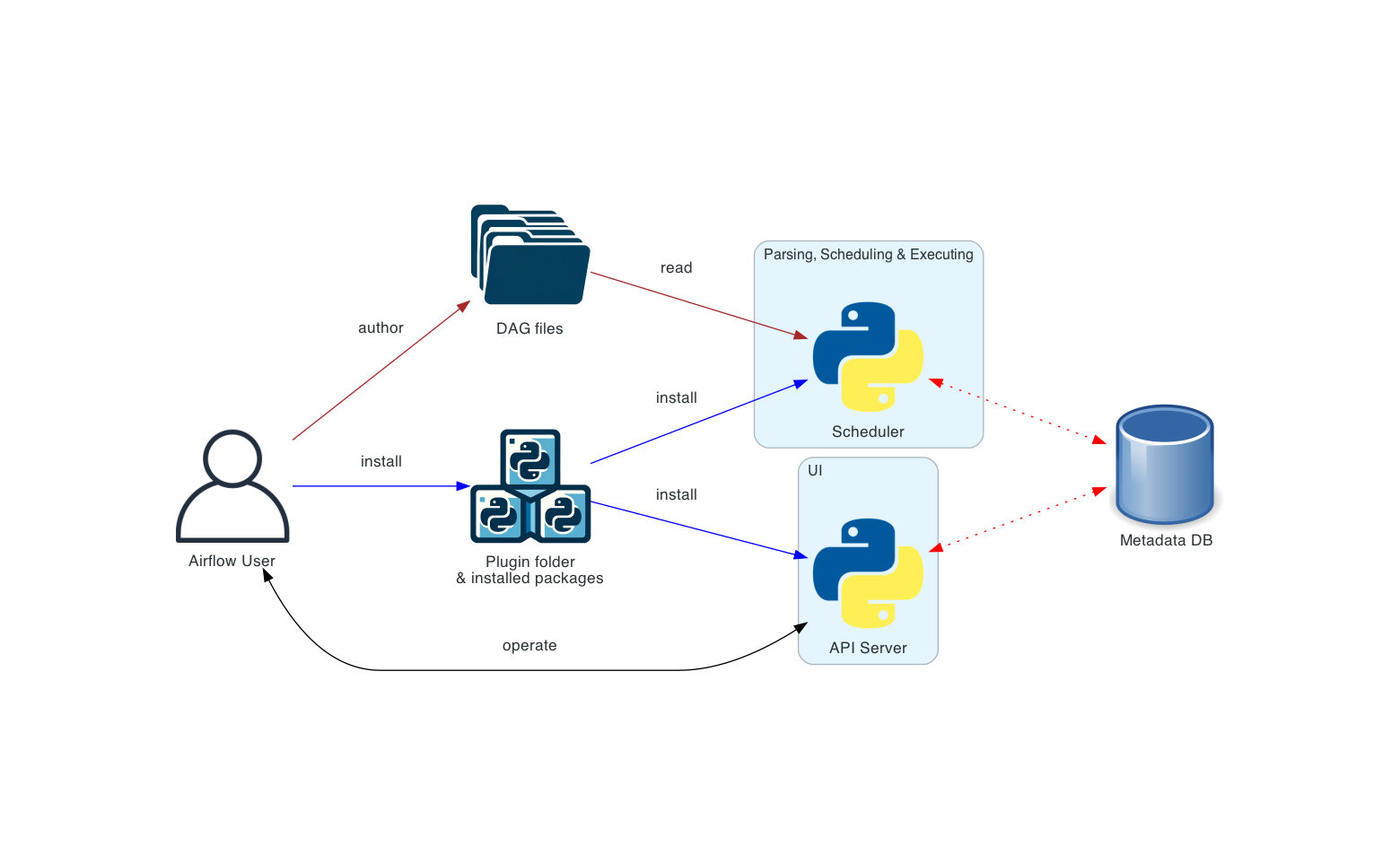
There are also other optional components, mostly related to parallelizing the work more effectively. Worth mentioning is the worker or executor. Here one can mainly choose between the default local, in the same process as the scheduler, or remote, via celery or kubernetes.
Lastly, the dags folder; while not a component per-se, it does behave as one.
It is the location where dags should be parsed from; quite literally, airflow imports everything in that folder
and keeps track of all the DAG objects encountered.
Then we have many providers, which are essentially extra libraries that provide an integration with another tool, such as Slack or postgres. Typically this means an extra Operator becoming available to use.
Dependencies
Oh boy; the list is huge.
Even though the model is to provide a core library with optional extras and providers,
there are quite a lot to go through.
We have alembic, sqlalchemy, and flask which, given the components listed above,
make total sense.
However the list goes on and on.
Why do we care?
The longer the list, the more clashes there might be with your project dependencies,
which, depending on how you run Airflow, might prove to be quite difficult to manage. Dependency Hell is a thing.
Then it’s also simply a matter of complexity; no matter the expertise, people do make mistakes
when it comes to dependencies, not to mention patching security issues.
Additionally, the more entangled they are, the more difficult it is to use the latest versions,
particularly those that introduce breaking changes.
For example, simply take a look at the comments in Airflow’s list for upgrading sqlalchemy.
In the wild
We have already mentioned the many available providers. There are additional practical integrations for logging, metrics, auth, etc. One can configure Sentry, statsD or even OpenLineage.
Then we have the “bundled” product, the one-click deployment that solves all your problems. Notable is the spin-off company, Astronomer, that offers a lot of extra features, most importantly a (technically) easy deployment to any cloud. But then of course each cloud has their own offering, such as AWS.
Deployment
Let’s take a break and look at some code before diving into other specifics.
Airflow can be deployed pretty much anywhere and there is a great checklist here. Airflow offers pre-built Docker images and Helm charts. This means one can also run it locally, albeit a bit more limited.
Why do we care?
What we care about is being able to test our pipelines easily, preferably locally during development, or at least via CI. We do not want to test in production. The more flexibility there is, the more likely it’s going to fit your architecture.
Locally
For development purposes, we can easily do the following:
conda create -n airflow python=3.12
conda activate airflow
pip install apache-airflow
airflow db migrate
airflow users create -u admin -p admin -f Ad -l Min -r Admin -e admin@gmail.comThen to run, in separate terminals:
airflow scheduler
airflow webserverAnd the UI will be available at localhost:8080 with example dags included.
Rant: looking at the logs of the scheduler, we can already see a fun dependency warning:
{workday.py:41} WARNING - Could not import pandas. Holidays will not be considered.We deserve no holidays, do we? So pandas is not required (and was not preinstalled) but certainly would be useful. This is not necessarily bad, however a pattern that imo ultimately causes issues.
OS
Mac & Linux are fine. But Airflow can only run on Windows via containers or the Linux Subsystem (WSL). Good luck, fellow corporate engineers.
Docker
Of course the local setup above is not that easily configurable, nor does it resemble a production setup. Airflow does provide a docker-compose one could use locally. This approach could more closely replicate what is done in production. For the purpose of the blogpost, skipping this one.
Kubernetes
Several options here too. Of course, in production there would likely be a kubernetes cluster in the cloud (or perhaps on-premise) to use. For now, let’s use kind and Helm to try it out on our machine. This is likely the option most closely resembling the actual production deployment.
After installing the tools and their requirements, all we need is essentially:
kind create cluster
helm repo add apache-airflow https://airflow.apache.org/
helm install my-airflow apache-airflow/airflow --version 1.15.0
kubectl port-forward svc/my-airflow-webserver 8080:8080 --namespace defaultA great feature here is gitSync, which one can configure to keep the dags folder in sync with a specific repo branch.
API
So how does airflow look like?
We have tasks which are subclasses of BaseOperator, such as PythonOperator or JdbcOperator.
They are either used directly, or via the newer taskflow API which are essentially decorators.
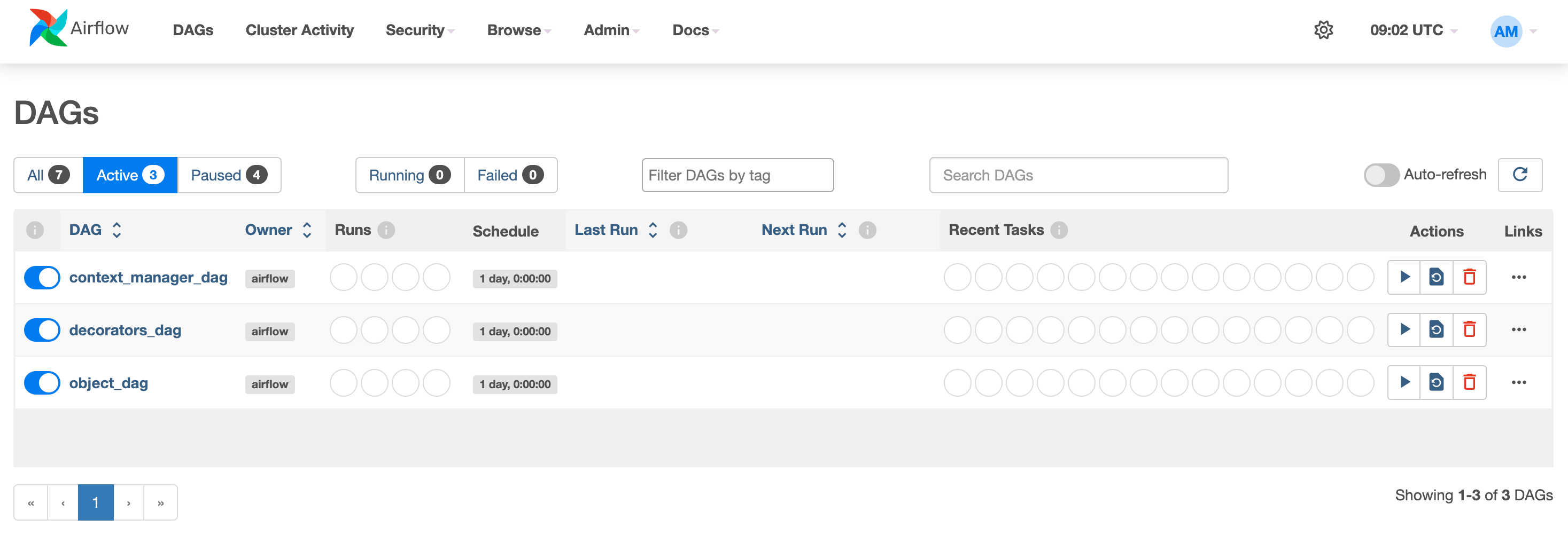
These tasks are then used within DAG objects created in one of three ways:
from airflow import DAG
from airflow.decorators import task, dag
from airflow.operators.bash import BashOperator
# context manager
with DAG(dag_id="context_manager_dag"):
BashOperator(task_id="bash_task", bash_command="echo 42")
# object
dag_object = DAG(dag_id="object_dag")
BashOperator(task_id="bash_task", bash_command="echo 42", dag=dag_object)
# decorators
@task.bash
def bash_task():
...
@dag()
def decorators_dag():
bash_task()
decorators_dag()Then one can see the DAGs in the UI:
Wait, so how are tasks linked together?
One can use the nicely visual bitwise operations, or the explicit functions.
task1 >> task2
# or
task.set_downstream(task2)Features
We already assume that Airflow:
- has a UI with an overview of all the workflows,
- can schedule those workflows,
- has logging and alerting capabilities.
These are the kind of features I’d expect all the orchestration tools to have, perhaps some better than others. These are also the kind of things one can easily see on the sales pitch page. We want to go over some use cases and how one could solve them with airflow. However without going too deep! Each topic could be its separate blogspost.
Uber-DAG
We have seen how to define a DAG but can we link DAGs together, or have sub-DAGs?
Linking them would typically be done by directly combining them in the same DAG (object).
When that is not possible, one could use an ExternalTaskSensor in the “child” or downstream
DAG and trigger them both.
The sensor task would then wait for the upstream dag to finish before continuing.
wait_for_upstream_dag_task = ExternalTaskSensor(
task_id="wait_task",
external_dag_id=parent_dag.dag_id,
external_task_id=parent_task.task_id,
...
)One can also group DAGs together in a TaskGroup for UI purposes.
with DAG(dag_id="taskgroup_dag") as dag:
do_this_task = BashOperator(task_id="do_this_task", bash_command="echo 'first this'")
with TaskGroup(group_id="grouped_tasks") as task_group:
do_this_subtask = BashOperator(task_id="do_this_subtask", bash_command="echo 'then this'")
do_this_other_subtask = BashOperator(task_id="do_this_other_subtask", bash_command="echo 'and this'")
do_this_subtask >> do_this_other_subtask
do_this_task >> task_group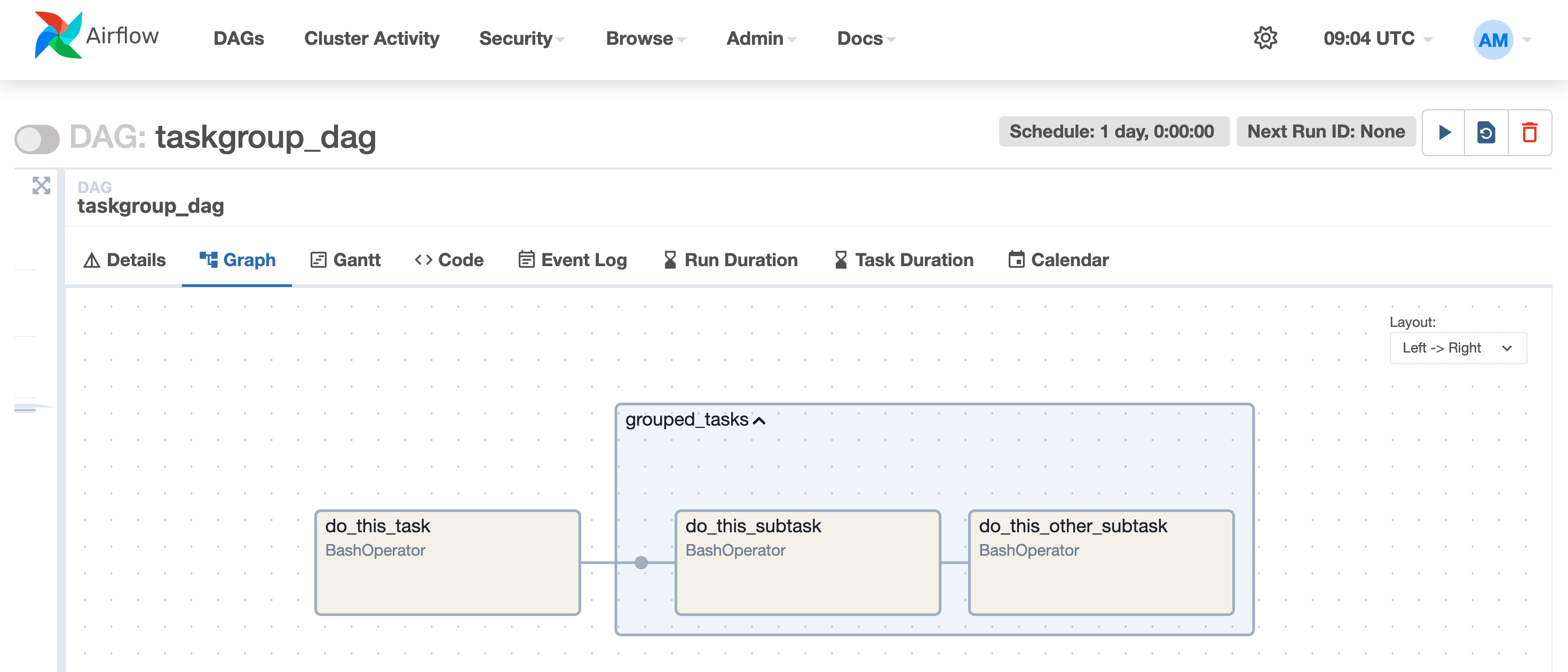
Triggers
What kind of triggers are there? Can we link DAG schedules?
We have already seen the ExternalTaskSensor which allows us to link a DAG to another.
There are however other sensors,
which primarily have 2 modes of working: poke every x time, usually every second, or reschedule later.
Here it is perhaps worth introducing the concept of worker slots.
Essentially all operators and sensors take 1 slot by default until finished,
and, as we’ll later see, one can configure a max limit using pools.
You might wonder though how do sensors fit in; do they just take slots forever?
With the reschedule mode, no; so the slot is freed until the next trigger time. This concept is however more generically available within Airflow via deferrable operators and sensors. Essentially the task is “paused” and its slot can be used by another task until a certain trigger point.
Wait but if the task is freed, how is this trigger point executed?
Here is where one of the optional components comes in: the triggerer. This extra process runs the deferrable tasks, which need to be async and are typically quite simple, such as “try again in 30 seconds”. On the API side, the default deferrable tasks actually look the same as their non-deferrable counterparts, for example:
sensor = TimeDeltaSensorAsync(task_id="wait_some_seconds", delta=datetime.timedelta(seconds=30))But let’s take a step back.
So we have these sensors which we could configure, for example, to poll data sources
and trigger a DAG once there is new data.
But we also have the “old school” cron schedules with some additional presets such as @daily or @continuous.
This is perhaps the simplest option to reason about when writing data pipelines.
Parallel DAGs / Tasks
Can we parallelize tasks? What about DAGs?
Yes and yes, with an asterisk. This is all about the chosen executor. There are 2 broad categories of executors: local and remote. Note that one can also easily implement their own custom executor.
Locally, the scheduler spawns a process per task, up to the configured limit. This essentially bypasses the GIL and is therefore bound by the CPU.
The remote category has two further subcategories: queued or containerized. Queued would rely on a queue backend, such as RabbitMQ or Redis, configured via Celery. Containerized would be, you guessed it, typically via Kubernetes. The remote option is the one that can theoretically be infinitely parallel.
Wait so what is actually parallelized?
DAGs execute in parallel by default. The tasks within them are however bound by the executor, as previously described. Do note that, since tasks are glued together in a DAG, of course the downstream tasks wait for the upstream to finish. This also means that a downstream task can depend on several upstream tasks that can themselves execute in parallel. For example, task1 and task2 here can execute in parallel:
with DAG():
[task1, task2] >> task3Which also means that one can configure in the code the “conceptual” parallelism separately from the “actual” parallelism applied on the machine, which is a nice plus. Furthermore, one can configure pools which allow setting global upper limits on the number of tasks that can run in parallel; and there can be multiple pools as well.
So we have 3 main parallelization options provided by the software alone:
- pools,
- DAGs,
- DAG
max_active_tasks.
Intercommunication
Can tasks send information to the next ones? What about DAGs?
Airflow provides XCom which is essentially a method to pass information from a task to another, possibly cross-DAGs too. One essentially pushes and pulls this information and, in certain operators, can use jinja templates. XCom is however not so intuitive to use. Here is an example:
with DAG(dag_id="xcom_dag"):
task1 = BashOperator(task_id="task1", bash_command="echo 42", do_xcom_push=True)
task2 = BashOperator(task_id="task2", bash_command="echo 'echoed {{ ti.xcom_pull(task_ids='task1') }}'", do_xcom_push=False)
task1 >> task2And one needs to know the specifics of each operator, for example in BashOperator,
the last command output is pushed.
Then we have the magic ti variable used to refer to the context of the previous task
which, via do_xcom_push, pushes an xcom with key return_value.
Wait, pushed and pulled where?
Well here the downsides are apparent. The data must be serializable and by default stored in the airflow database. So one would ideally only pass a few strings, if needed. For data, would pass the path to data, or a table name; but not the actual data itself. Internally, XCom are similar to Airflow variables, which are generic key-value pairs.
There is however the option to configure an object store instead of the default
database via XComObjectStorageBackend.
Technically, one could even combine the two, but this does not come out of the box.
So one cannot rely on Airflow just passing the data in memory from a task to another, even if the tasks run on the same machine. Recall the tasks are separate processes at the minimum. This also implies one cannot split the code conceptually into multiple tasks without writing the intermediary results somewhere.
Gimme resources
How does it handle huge load? Where are the bottlenecks? Can it autoscale?
Well in short, Airflow won’t do this for us, which is understandable. For example, for Airflow to manage the resources available in a Kubernetes cluster, it would need to understand everything about it in the first place, which is just like reimplementing Kubernetes.
So what happens then?
The infrastructure is managed by you. Practically, this means being aware of the capabilities of your machines and configuring limitations where appropriate.
Let’s take the example of the Kubernetes cluster. Airflow will simply trigger the tasks according to the schedules, with no regard as to whether there are resources to process them. So when the cluster is at capacity, pods won’t be allocated by Kubernetes and the tasks will fail. Worse, tasks can also be killed pseudo-arbitrarily, if starting new tasks could lead to the total resources required exceeding those of the cluster; which again, makes sense from Kubernetes’ perspective.
So what can we do?
One common guideline is to configure Kubernetes tasks with the resource requests and limits close together or even the same value. Ideally, Airflow would run in its own cluster so as to never compete for resources with other applications.
task = KubernetesPodOperator(
name="k8-task",
resources={
"request_memory": "2Gi", "request_cpu": "500m",
"limit_memory": "2Gi", "limit_cpu": "500m"
},
...
)Then, Kubernetes or not, we have the parallelization options mentioned above. This does require manually being aware of the resources limits and the DAG requirements. Could perhaps even get creative and programmatically check these in the codebase.
Task Types
Long-running
Can we have a never-ending job, e.g. to poll a database for new data?
Yes!
We talked about the @continuous cron schedule or the perhaps more appropriate
deferrable sensors.
Streaming
Can we do streaming?
Maybe. What do we really mean by streaming here?
Streaming in its purest sense never ends and is expected to perform very fast; think milliseconds latency and technologies such as Kafka or Flink. Streaming in this sense is a whole different beast to traditional batch processing and requires its own tools.
Airflow was not designed for it. However, with a more loose definition of streaming, such as “update these tables as soon as there’s new data”, then yes, sure.
One can configure sensors and have DAGs update the data relatively fast, but as soon as you do this with a high cadence, say, every minute, you will notice the UI quickly get full and become fairly useless. Fixing failed runs will become very tedious and the database will be pushed to its limits with all the essentially useless logs.
Blitz
Can it handle very small tasks efficiently?
Yes! Or mostly.
There is of course an overhead to the scheduling, tracking, logging, etc. that Airflow does for us. Then IO is also expensive, highly relevant when DAGs constitute a bunch of iterative processing steps on essentially the same input data. On top of that, using a remote executor such as Kubernetes will add its own overhead.
So tasks should be more complex in nature. We talked about how each task is a process and how the only way for them to communicate is via xcom which is IO on a filesystem. Do not split as separate tasks e.g. reading from a table and processing a column, as it will take much longer to finish than simply combining these steps into a single task.
Other Engines
Can we use something else than vanilla Python for processing, e.g. a tool like Spark?
Yes! One can use pretty much anything as long as it is possible to trigger it from Python. There are Spark operators, a Docker operator, JDBC operator, and many more.
Fault tolerance
How fault tolerant is it and how can you recover from failure? Can we backfill?
There are several topics here.
Let’s first consider what happens when Airflow itself is down. If a single component is down, everything else should work as expected. The webserver, for example, can be down without affecting the processing. If the scheduler is down however, everything stops.
Here Airflow is actually a step ahead of us: one can setup more than one scheduler. This will provide better resiliency. The same thing could be done for other components too. Here it really depends on the chosen deployment model, Kubernetes being very flexible in that regard.
Let’s now consider a task failing which has nothing to do with Airflow itself. Given tasks are connected through a DAG, Airflow automatically marks as failed everything downstream from the failed task with the appropriate status message. To recover and fix the error, one could simply retrigger the DAG manually via the UI. This means that the tasks and well the workflows themselves should ideally be designed and written in an idempotent fashion to avoid any duplication issues.
Why not retrigger only the failed task?
Well Airflow won’t allow you, at least not in an obvious way via the UI. One can clear tasks in the UI one-by-one to make them re-run, or even retrigger a task via the CLI (though then the UI could become out-of-sync). However the point here is that the overall design in Airflow is for DAGs to be a group of tasks that are meant to be “in-sync”.
One can however configure for example retries on tasks, such that
some of the fault tolerance is taken care of immediately.
We have retries, retry_delay, and even retry_exponential_backoff.
It would be a shame to throw hours of work done by previous tasks away, just
because a simple notification task downstream failed.
Again, it is important to design the workflows as idempotent, which also
implies the individual tasks to be able to avoid re-processing the same things
again (unless required).
from datetime import timedelta
retrying_task = BashOperator(
task_id="retrying_task",
retries=3,
retry_delay=timedelta(seconds=30),
retry_exponential_backoff=True,
...
)What if a run failed but then the subsequent one succeeded?
Once again, it depends on the content of the workflows. A common pattern with Airflow is, if subsequent runs fix the previous runs, to manually mark the previous runs as succeeded. This is not necessarily nice from the statistics perspective, however from a data “status” perspective might make sense. If there are gaps in the data, we should see that as red, but if there aren’t, it should all be green. Then for statistics purposes, e.g. how many failures per day, one still has the logs.
An alternative, and perhaps the way the original creators had in mind,
is that each DAG run is truly fixed in time, say run1 processes the data for year 2023
while run2 processes for year 2024, and so on.
In that case, simply retriggering the DAG won’t fix the past, which is why Airflow
provides the backfill command which essentially triggers a DAG run with an old timestamp.
This however and as hinted, can be tricky to reason about correctly, hence from my experience,
the previous approach is more common.
Astronomer go in even more details about these topics here.
Dev Flow
How does development look like with Airflow?
Airflow needs to read the dags from a specific dir and implicitly on a specific branch, say main.
This means that one would only have the main branch deployed on each environment, which begs the question:
how do I test my changes?
The ideal scenario is to simply run Airflow locally. One can be on any branch and modify the dags folder content as they see fit. Once tested, simply merge and deploy; easy.
But we all know that actually running the tasks may not be possible from our machines. This is not even about the data size, but even simply auth not being allowed outside of the chosen deployed environments. Running Airflow locally might also not be possible due to a tool or library not being allowed (or possible) to be installed; looking at you Windows.
The perhaps second ideal scenario is to have a DEV environment one can deploy their branch on. This however comes at the cost of complexity and speed. Ideally this environment would have its own data but we know how maintaining that takes more effort than expected.
Why did you keep mentioning the dags folder specifically?
Well the dags folder needs to be fixed, however what runs within the tasks could be stored and version controlled elsewhere. For example, say tasks are simply calling a CLI to process data. The CLI only needs to be installed on the actual executors; as long as Airflow can simply parse (import) those Python files in the dags folder, all good!
Be creative.
Testing
How to test individual tasks or a whole DAG?
Airflow actually provides a test method on DAGs which allows running them without
an actual Airflow deployment; in other words, directly on the machine running the Python code.
Again the same caveat that the whole DAG is run, not individual tasks.
One can however pass a pattern to automatically mark certain tasks as success which
essentially achieves the same thing.
We already hinted towards the “macro” or “integration” test one could do by deploying the code to a dev environment. What is left is the “micro” or “unit” tests which one can of course do however they see fit; it is Python after all.
Review
We have reached the most subjective section, namely how I would describe working with Airflow. What went smooth, what did not, what issues have I identified.
Disclaimer: I have used Airflow professionally in two different teams. The details and rants here come from personal experience along with experiments on my own.
Setting up Airflow actually went smooth, as long as I stuck to the “simple” ways of using it. As soon as Kubernetes was required, it became quite a headache. The documentation is definitely lacking in this regard. What might seem obvious to the authors, requires a lot of trial-and-error.
For example, one might think that using the KubernetesExecutor along with
the KubernetesPodOperator makes perfect sense.
Once you start doing that though, you realize you have double the pods you expect,
and configuring their resources and some isolation between the “master” and the “slave”
pods is incredibly tedious.
Airflow also does not (understandably) manage the Kubernetes cluster for you,
which means this burden of managing the infrastructure still falls on you.
Overall however, particularly since Airflow version 2, the user experience is good. Once everything is set up, adding new or updating existing DAGs goes smooth. The UI feels snappy and most workflows are covered.

There are though certain peculiarities that seem counter-intuitive to many. For example, given a daily schedule, the date shown and used to process today’s data is tomorrow; even if it runs today. This comes from the original design of batch processing where “fresh data” of tomorrow would mean processing everything from today.
We have also seen how really the main Airflow “unit” is the DAG, not a task. One triggers, maintains, and monitors DAGs as a whole, which might come as a surprise. In a complex environment with a lot of datasets, particularly in pipelines that rely on different schedules and update mechanisms, one might end up with a LOT of DAGs, just to be able to more easily schedule everything.
Lastly the documentation, while thorough, it is now perhaps too big. Things go out of sync and some details are not actually searchable correctly. Take Sentry for example, where the Airflow documentation search fails to give a valid result. Many topics are also not exemplified, hence the code samples in this blogpost too.
Summary
We went through several topics in an attempt to give a more realistic picture of using Airflow as an engineer, covering both challenges and day-to-day dev flow. We went over the deployment options, how the API looks like, and many use cases. We have seen the parallelization options, possible integrations, and fault tolerance.
Overall, I find Airflow is still a valid choice, though I am always left looking for a more modern option, something more intuitive to use, with up-to-date and concise documentation, and fewer dependencies.
Addendum
We need more code examples!
Since this is a (very) long blogpost, will likely extract specific how-to’s in separate #short posts but with more examples. Stay tuned!