Data Lineage via OpenLineage - The Easy Way
Published on Jul 1, 2024
Last updated on Mar 3, 2025
10 min read

Prelude
Data Lineage seems to be something that is never requested yet highly valuable. The kind of knowledge you don’t know you need; or maybe you do, just not how to obtain it.
Quick poll: how many of you have received these kind of messages before?
What creates this data? I can’t find anything in the codebase referencing this table!
Hey, how is this data in PROD but not in DEV?
Why is this table not updated even though everything before it is updated?
It is easy to just “ping that guy, they know” but is that really the best way?
What are we trying to solve exactly?

There are a bunch of challenges here, besides the beloved dev tribal knowledge.
We have data governance as a whole, with solutions popping up recently such as Databricks’ Unity Catalog. More specifically though, I would emphasize discoverability. Developer or business, we need to know what datasets exist and where. Rarely is data stored in a single place. Think of all the departments in a large corporation and the multitude of purpose-built software in all of them.
Then we need to know how those datasets exist. What creates them? What updates them? Can they be deleted? Yes, their CRUD operations. The data life cycle.
Wait, why should business know which code does this?
Well, not the code, but which people were and still are involved, definitely. Content-wise, business would likely know even more than the developer about the data itself and the meaning behind it; or so would one expect.
And finally, the point of this blogpost: their lineage. How are the datasets connected? Where does this column originate from? How to track this information across systems? Even with the same underlying data, it may be:
- stored in several places under different data models,
- following different data life cycles,
- managed by different people with different mental models around it.
So what do we do?
The Engineer, as always, prefers simple solutions. Wouldn’t it be nice to just have this information collected automatically in some centralized place? You would probably need another database of sorts (ironic, isn’t it?) and a way to visualize it. Let’s even ignore the access requirements, networking, and the likes for now.
Hey, we already have tools for this!
Dagster? dbt? Prophecy? And I am sure there are more. They all provide some data lineage information. Yet take a look at the long list of dependencies to run those. Then also look at their limitations. Likely Python-only or only working within their own environment.
We need something more generic. Some sort of standard.
Sure, could build something in-house but then you are essentially locked in. And why do that when we already have an open source standard available under OpenLineage?
Solution = OpenLineage?
Originally an LF AI & Data Foundation project contributed by Datakin and since acquired by Astronomer. Astronomer, for those unaware, is “the” data platform built on top of Airflow. Now was the acquirement a good thing? Who knows. The OpenLineage project though is still active on GitHub. And I believe it’s a good step forward.
OpenLineage proposes a standard to follow. It decouples the actual lineage data from the presentation, i.e. the UI.
The data model is simple. There are datasets, jobs, and runs aka executions. Each of these assets can be easily extended with custom metadata to support any scenario. Jobs can also contain other jobs; highly flexible.

It is practically an event-driven pattern. One sends events in the form of STARTED and COMPLETED. And you don’t really need more than that.

These events can be sent via API or simply dumped somewhere, e.g. file or console. In a sense, they are simply log entries. Given one sends beginning and end -like events, one can easily extract the duration for each step. No more need for custom timing steps in the codebase. Even better, one can out-of-the-box see how long something takes end to end across various systems. Isn’t that neat?
One sets namespaces to segregate the events. The obvious use case here is between the different dev environments.
Since it is just a standard, it can be applied in whatever programming language. The team behind OpenLineage already offers easy-to-use libraries for main languages such as Python and Java.
All that remains is to access these log-like events and visualize the lineage. Here a default implementation is provided via Marquez, another LF AI & Data Foundation project from WeWork which was, interestingly enough, contributed before OpenLineage. Now because of this history, there seems to be some level of coupling between these two projects which is not very nice, as we will get to later.
Proposal
Now this has been pretty wordy so far. Let’s see something practical.
Recall what we’re trying to do:
- send OpenLineage events somewhere,
- visualize the lineage,
- minimal existing codebase changes,
- minimal dependencies.
The Engineer would emphasize the last point. We want something simple that does it well; Unix Philosophy anyone?
Setup
We have three components to set up:
- The storage of lineage events; here we choose the Marquez default of Postgres.
- The visualization of those events; yes, you guessed it, Marquez.
- An event producer; in this blog post we choose a simple Python decorator but hint we could do smarter things too :)
We use Docker Compose for points 1 & 2. After some unexpectedly high effort required to figure this out, the below seems like the minimum necessary locally.
services:
api:
image: 'marquezproject/marquez:0.47.0'
container_name: marquez-api
environment:
- MARQUEZ_PORT=${API_PORT}
- MARQUEZ_ADMIN_PORT=${API_ADMIN_PORT}
ports:
- '${API_PORT}:${API_PORT}'
- '${API_ADMIN_PORT}:${API_ADMIN_PORT}'
depends_on:
- postgres
volumes:
- ./scripts/api:/opt/marquez
networks:
- marquez
entrypoint:
- /opt/marquez/wait-for-it.sh
- postgres:${POSTGRES_PORT}
- --
- ./entrypoint.sh
postgres: # marquez expects it to be at "postgres" host
image: postgres:14
container_name: marquez-db
ports:
- '${POSTGRES_PORT}:${POSTGRES_PORT}'
networks:
- marquez
volumes:
- ./scripts/db:/docker-entrypoint-initdb.d
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
- MARQUEZ_DB=marquez
- MARQUEZ_USER=marquez
- MARQUEZ_PASSWORD=marquez
web:
image: 'marquezproject/marquez-web:0.47.0'
container_name: marquez-web
environment:
- MARQUEZ_HOST=api
- MARQUEZ_PORT=${API_PORT}
ports:
- '${WEB_PORT}:${WEB_PORT}'
depends_on:
- api
networks:
- marquez
networks:
marquez:And in ./scripts we have 2 scripts:
Finally, to run, we need to set up and pass some environment variables.
API_PORT=5002 API_ADMIN_PORT=5001 WEB_PORT=3000 POSTGRES_PORT=5432
docker compose -f ./docker-compose.yml up -V --force-recreate --remove-orphansPython
Create your Python environment. Using conda as an example:
conda create -n openlineage python
conda activate openlineage
pip install openlineage-python==1.16.0First we need a decorator. If one thinks about lineage, the bare minimum to track consists of 3 things:
- inputs,
- outputs,
- job name, here function name.
So we want something like:
@lineage(inputs=["source_table"], outputs=["output_table"])
def job():
...Which would minimally look like this:
from typing import Any, Callable, Iterable
from uuid import uuid4
from openlineage.client.client import OpenLineageClient
def lineage(inputs: Iterable[str] = list(), outputs: Iterable[str] = list()):
def lineage_inner(func: Callable):
def wrapper(*args: Any, **kwargs: Any):
client = OpenLineageClient()
function_name = func.__name__
# same run_id but different state transition
run_id = str(uuid4())
emit_job_start(client, function_name, run_id, inputs, outputs)
result = None
try:
result = func(*args, **kwargs)
except Exception as e:
emit_job_fail(client, function_name, run_id, e, inputs, outputs)
else:
emit_job_complete(client, function_name, run_id, inputs, outputs)
return result
return wrapper
return lineage_innerYes, we should use functools.wraps, perhaps functools.cache the client, and others, but keeping it simple here.
Now for those emit_* functions:
from datetime import datetime
from typing import Any, Callable, Iterable
from openlineage.client.client import OpenLineageClient
from openlineage.client.event_v2 import (
RunEvent,
RunState,
Run,
Job,
InputDataset,
OutputDataset,
)
def emit_job_start(
client: OpenLineageClient,
job_name: str,
run_id: str,
inputs: Iterable[str] = list(),
outputs: Iterable[str] = list()
) -> None:
namespace = "default_namespace"
event_time = datetime.now().isoformat()
run_event = RunEvent(
eventType=RunState.START,
eventTime=event_time,
run=Run(runId=run_id, facets=dict()),
job=Job(namespace=namespace, name=job_name),
producer="", # let openlineage set default
inputs=[InputDataset(namespace, inp) for inp in inputs],
outputs=[OutputDataset(namespace, out) for out in outputs],
)
client.emit(run_event)
def emit_job_complete():
...
def emit_job_fail():
...Omitted the remaining 2 emit_* functions, though they are very similar to emit_job_start.
Example Pipeline
import os
os.environ["OPENLINEAGE_URL"] = "http://localhost:5002"
@lineage(
outputs=["source"]
)
def read_inp() -> int:
return 1
@lineage(
inputs=["source"],
outputs=["processed"]
)
def add_one(inp: int) -> int:
return inp + 1
@lineage(
inputs=["processed"]
)
def log(inp: int) -> None:
print(inp)
if __name__ == "__main__":
inp = read_inp()
out = add_one(inp)
log(out)Note the openlineage config. We need to tell it where to send the events, otherwise it defaults to writing to console. So what we did is decorate the functions with their inputs and outputs. This is it.
We can then open Marquez to visualize after running the pipeline once. First, the list of events that were generated.
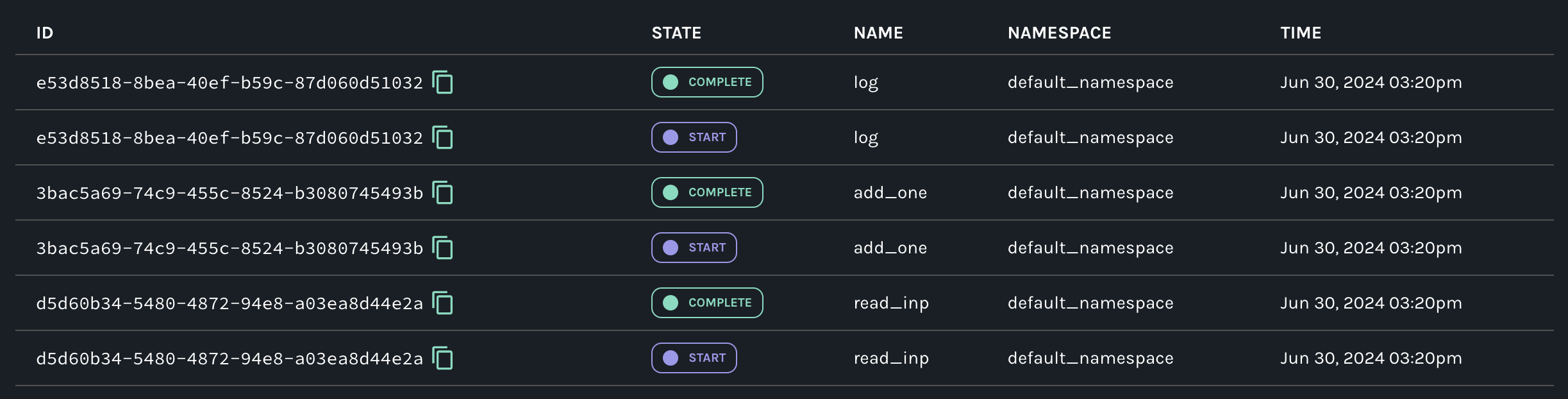
Notice the ID matching the corresponding START and COMPLETE events for a given job NAME. Clicking them exposes the entire event payload as JSON with its specification here.
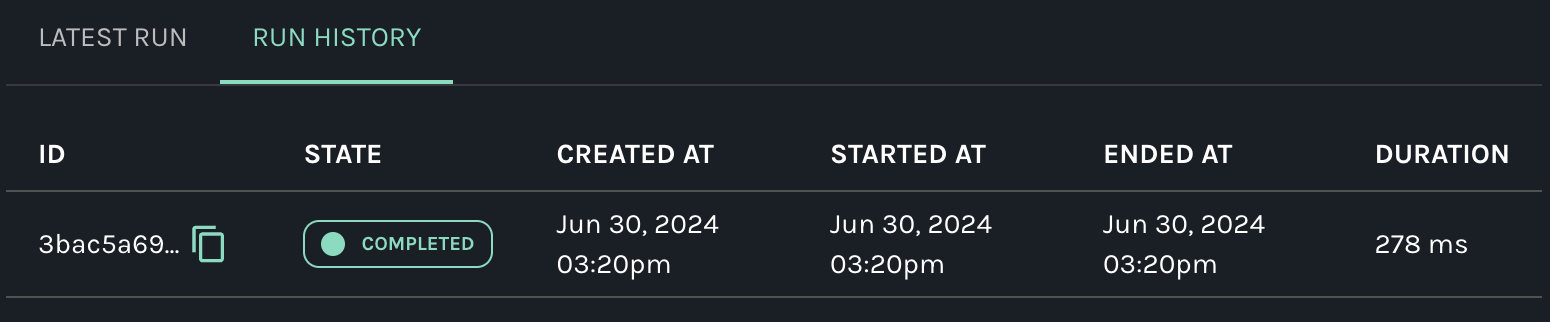
In a different tab we see the desired lineage, showing the datasets and how they are connected via jobs. Clicking on a job exposes more details, such as its history and automatically computed duration. Similarly, clicking on a dataset exposes its version and other metadata, such as columns, data types, or tags, if provided.

Last words
Well this is it.
We created a Python decorator which sends events to a DB for Marquez to display.
We saw a brief and practical introduction to OpenLineage concepts via the openlineage-python library.
It could have been even easier, however there is still much potential here. The Engineer will definitely keep prototyping around OpenLineage. After all, manually specifying the inputs and outputs and updating the codebase is not that fun. What if we could do these steps automatically? Stay tuned :)
Addendum
This requires so many code changes. Is there no automation possible?
A big challenge here is inferring the names of things, both jobs and datasets. Thinking about data pipelines in general, usually these names are either hardcoded or specified in certain configuration files. I have never seen a project doing it the same way as another.
Sometimes we might also want to skip certain steps, such as intermediate computation steps which may or may not materialize datasets. Perhaps one would like to not show them all or provide certain views on-top which cannot be accomplished via namespaces alone.
This also shows that the lack of more well-known data lineage tools might simply be because of the vast complexity and variety in Data Engineering. Nevertheless, I do believe there are ways to improve things in this area.
You hinted that there were difficulties in setting this up. What were they?
I believe making it work was more challenging than it should be. Perhaps this is feedback for the maintainers, or simply a rant.
The default Docker images and instructions are bloated and not really documented. They seem to have been written for some specific use cases (which I get), but this is a barrier to other people prototyping with them.
There seem to be 2 versions of abstractions in the codebase, with cross dependencies, as evidenced by the event_v2 imports.
Many API endpoints seem to have been removed in Marquez docs.
Seeing all these in the same code version is dirty; perhaps it could have been tackled more cleanly via semantic versioning.
Which leads to the relationship between OpenLineage and Marquez: it is confusing. They both have Python libraries and abstractions over the same things. It is hard to figure out when to use one or another. Likely there are historical reasons here, but these are again barriers to wider adoption.
Why is this flying under the radar? Why are not more people talking about this?
As hinted throughout, there are several challenges I see. First, it is hard to justify the need for it when the default is “ask that person” for these kind of questions. Tribal knowledge is very common and hard to change.
Second, the lack of a popular and generic-enough tool in the back of people’s minds. When exposed to these kind of issues, the immediate thought is to write documentation or simply maintain the status quo which seemed to have worked well-enough in the past. How can a better tool be brought up if people do not know it exists?
Lastly, it is hard to justify the need for it when it does not have an immediate business impact. Why would people with busy schedules bother with yet another tool when there are always bigger issues to tackle?
Nevertheless, The Engineer believes that the more exposure to the topic, the more understanding will be brought to the benefits of maintaining such lineage information. It does not have to be OpenLineage; it must however be something that will decrease the tribal knowledge phenomenon.